Alerts
Navigation Notice: When the APM Integrated Experience is enabled, Loggly shares a common navigation and enhanced feature set with other integrated experience products. How you navigate Loggly and access its features may vary from these instructions.
An important part of any log management system is alerts. Loggly’s paid plans (Standard and Pro) include alert functionality. Loggly monitors for you, and you don't have to search your log data for specific events. Loggly runs your saved searches on a predetermined schedule and send emails or messages to your chosen endpoint when search results fall within a set band and meet the criteria you establish.
There are three main components to an alert:
- Alert threshold: How often the condition should be monitored and the number of events (or lack of events) that should trigger an alert.
- Search: A description of the terms and conditions of the alert.
- Endpoint: Where you want the alert sent (choose a user's email account or a trigger to a third-party endpoint). Loggly supports generic POST/GET endpoints and offers integration with Alert Birds.
See below for more information on adding alerts and configuring alert endpoints.
Alert Scenario Examples
- Alert if you have less than 10 sign-ups per hour. Your saved search might look like:
apache.request:success
- Alert if your response time is greater than 3 seconds more than 5 times per minute. Your saved search might look like:
json.response_time:[3 TO *]
- Alert if there are more than 10 errors in a 30 minute period. Your saved search might look like:
apache.status:500 OR json.exception:error
Configuring Alerts
There are three ways to set up alerts in Loggly:
-
By clicking Add New from the Alerts List.

-
By performing a search, and then clicking the star icon to the right of the Search button.

-
By clicking the bell icon to the right of the Search window.

Regardless of how you begin creating your alert, you are prompted to provide the following information:
- Name. Choose a name for your alert. The name is returned with any alert that is triggered.
- Description. Add a short description so you remember why you set up the alert.
- Search. Select a Saved Search to use.
- If you initiated your alert setup from the Saved Search creation dialog, that saved search displays.
- If you initiated your alert setup using the bell icon, you can see custom search context and the details of the current search you were performing. Any time range that was part of your saved search is ignored. Only the terms of a saved search are used for alerts.
- Alert if. Establish the criteria to trigger an alert. Set the threshold number of search results that trigger an alert within a given time frame. For example, you can set an alert to trigger when the search shows more than 10 results over any 5 minute span (based on time stamp).
- Then. Establish how you’d like to receive notifications. Options are to send the notification to an email or a third-party endpoint. See Alert Endpoints for information on setting up your own endpoints. Only registered users can receive email notifications.
- Check for this condition every. Identify how often to run your saved search and scan for the number of results that match your alert criteria. If you choose to check for the condition every minute and the condition exists for 30 minutes, 30 notifications will be sent.
- Add Multiple Endpoints. Set multiple endpoints to receive the notification from an alert. For example, you can set an alert to notify both your Microsoft Teams channel and your Slack room without the need to create a second alert.
- Include up to 10 recent events. Enable this option to receive up to 10 recent events as part of the alert.
- Check for this condition every. Set how often to run your saved search and check whether the condition matches your alert criteria. If you choose to check the condition every minute and the condition exists for 30 minutes, 30 notifications will be sent.
- Delay alerts during indexing delays. This may reduce false positives. Enable this setting to help you avoid false positives. For example, if this setting is not enabled and your account is experiencing an indexing delay, the alert might trigger due to absence of expected events caused by the indexing delay. When enabled, an alert is not sent until the indexing delay is recovered and back to normal.
- Enable this alert. Clear the check box to inactivate an alert, but keep it saved so it can be enabled in the future from the Alerts page.
Alert Types
Standard Deviation
Using a Standard Deviation alert type, you can specify the threshold of the trigger in relative terms using standard deviations. This statistical operator is a measure that quantifies the amount of variation in a set of data values. While a low standard deviation indicates that most of the values in the data set are close to the average, a high standard deviation indicates that they are distributed over a wide range of values.
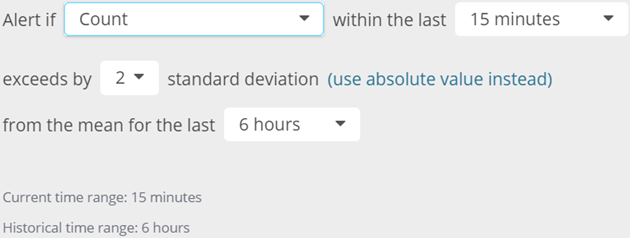
If you are tracking 404 errors, the example setup would alert when the count of 404 errors in the last 15 minutes is above two standard deviations from the average for the last six hours. 404 errors are a way of life, so setting an absolute threshold often does not make sense. But you would certainly want to investigate a sudden 404 spike. In this case, you can specify whether you would like to be alerted on one, two, or three standard deviations from the mean. Mathematically speaking, this implies that you can choose to be alerted when some values exceed 68%, 95%, and 99% from the mean, respectively.
Percentile
The Percentile alert can be used to identify whether an issue is a severe problem or an outlier.
For example, if a customer complains about your application’s performance, and log data shows that the customer experienced a page load time of almost 15 seconds, you would need to determine whether the customer encountered a severe problem that affected many other customers or whether the incident was an outlier.
Percentiles allow you to quickly determine the answer by looking at all the load times recorded in your log data.
For example, if a load time of 15 seconds is in the 95th percentile, it would mean that 95% of users received page load times better than 15 seconds. The long load time could be identified as an outlier and not part of a larger group. Percentiles make this analysis easy even when you are dealing with a large number of log events.

Percent Difference
The Percent Difference alert allows you to get notified if a value changes by a given percentage compared to a specific time period in the past. If you are interested in monitoring an abnormal number of errors, you can set up a Percent Difference.
For example, an alert for the count of 403 errors in a rolling window of 30 minutes jumps by 20% as compared to the count of errors during the last day would look like this:
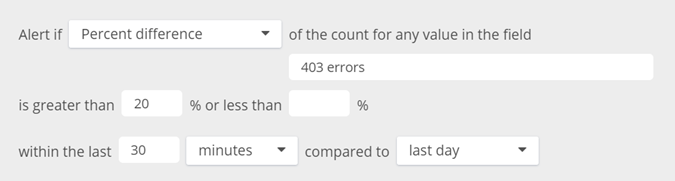
Loggly compares the difference of percentages within the scope of all events in a given search–NOT absolute numbers.
Anomaly Significance Score
Anomaly Detection highlights anomalies in your logs that come from major changes in the frequency of certain log events. For example, you can immediately see whether you have a big increase in errors after a new code deployment, a jump in Amazon EC2 configurations, or an unusual number of user log-in failures that could signal an attacker looking for vulnerabilities.
However, it is not uncommon for situations you considered to be the ones that cause issues. Anomaly detection alerts are a way to find out about things you haven’t anticipated. You can tell Loggly to notify you of anything that deviates from normal levels in the log fields you monitor.
For example, because the syslog.severity or json.level fields in log messages contain a lot of information, you might have a baseline level of ERROR and CRITICAL messages that wouldn't signal trouble. But if the values were to steadily increase over time, they might signal trouble. If your normal ratio were 90% INFO and 10% ERROR and CRITICAL messages, a Loggly anomaly detection alert would notify you if any of these values deviated from normal beyond a defined threshold. You could then go directly to the relevant events in Loggly to investigate.

Loggly analyzes countless field values simultaneously as it ingests your logs, determines the normal value ranges in them, and brings those with the biggest changes to your attention in near real-time. You can see any significant deviations, even those you may not have thought about. Anomaly detection allows you to take action before the anomalies turn into problems.
When an anomaly significance score is higher, it means a big anomaly exists. The alert takes into account the change from the background time range and the size of the value relative to others. The score doesn’t really have any meaning in an absolute sense. The meaning is only relative to the other field values.
Alert Suppression
You may want to suppress alerts when an outage is planned, for example a maintenance window or system upgrade. Alert Suppression prevents alerts from being sent and disrupting your support team. Additionally, you may want to suppress alerts to avoid duplicate alerts after you have acknowledged a problem. Alert suppression in these cases can help you avoid being inundated with information you are already aware of and help you focus on information that can help resolve issues at hand.
After alerts are configured and you are receiving them, you can follow the instructions below to set alert suppression parameters.
- On the Alerts page, identify the alert you want to suppress. If this alert is not currently suppressed, the None values are displayed. To set suppress parameters, select the None link. If an alert is not active Loggly displays an N/A to indicate that you cannot suppress it.

- A window opens with the Alert name (example: a SLA Responses to Teams). In the Suppress Alert for field, specify a number value for the number of minutes or hours you want to suppress the alert. If you change the suppression time for an alert that is already suppressed, the previous value is replaced.